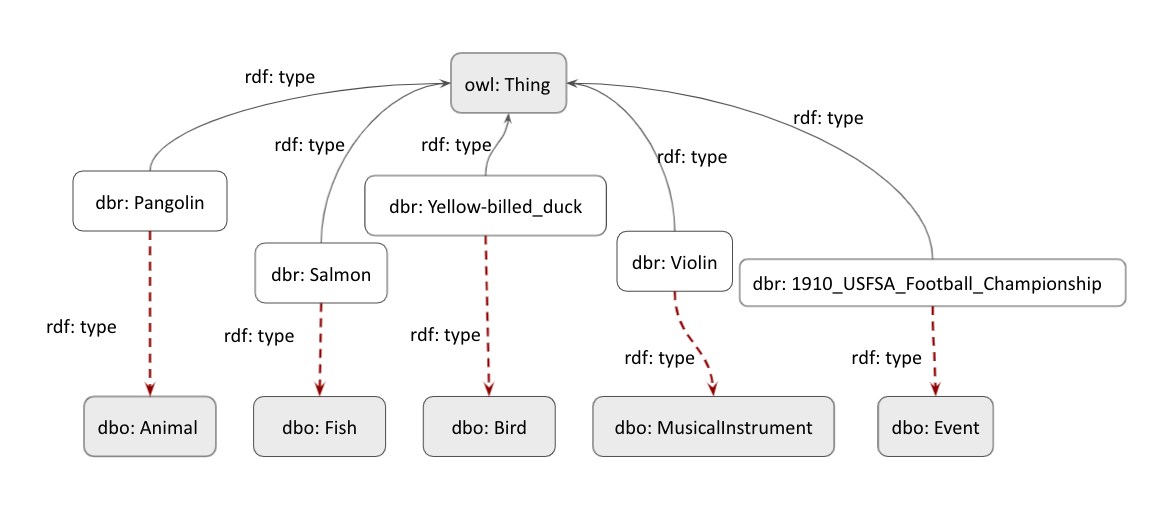
This work focuses on predicting the entity types solely from their label names, e.g., What is pangolin?, or What is a violin?. As humans we have the background knowledge that pangolin is an animal and violin is an instrument. There are many such entities in DBpedia as depicted in the figure above for which the entities are typed to the most general class owl: Thing. Neural Language Models (NLMs) are exploited to predict the types of the entities.
Language Models
Language modeling is the art of determining the probability of a sequence of words. This is useful in a large variety of areas including speech recognition, optical character recognition, handwriting recognition, machine translation, and spelling correction.
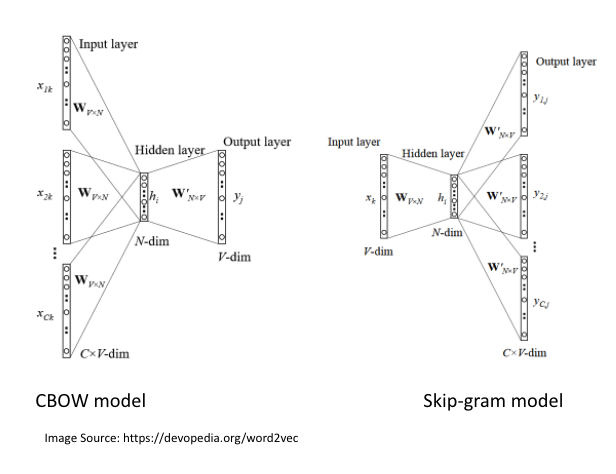
It aims to learn the distributed representation for words reducing the high dimensional word representations in a large corpus. The CBOW Word2Vec model predicts the current word from a window of context words and the skip-gram model predicts the context words based on the current word. In the figure, the model consists of a vocabulary of V words, a context of C words, a dense representation of N-dimensional word vector, an embedding matrix W of dimensions VxN at the input and a context matrix W' of dimensions NxV at the output.
GloVe exploits the global word-word co-occurrence statistics in the corpus with the underlying intuition that the ratios of word-word co-occurrence probabilities encode some form of the meaning of the words. It is essentially a log-bilinear model with a weighted least-squares objective.
The training objective of GloVe is to learn word vectors such that their dot product equals the logarithm of the words' probability of co-occurrence. Owing to the fact that the logarithm of a ratio equals the difference of logarithms, this objective associates (the logarithm of) ratios of co-occurrence probabilities with vector differences in the word vector space. These ratios encode some form of meaning of the words, hence, this information gets encoded as vector differences as well.
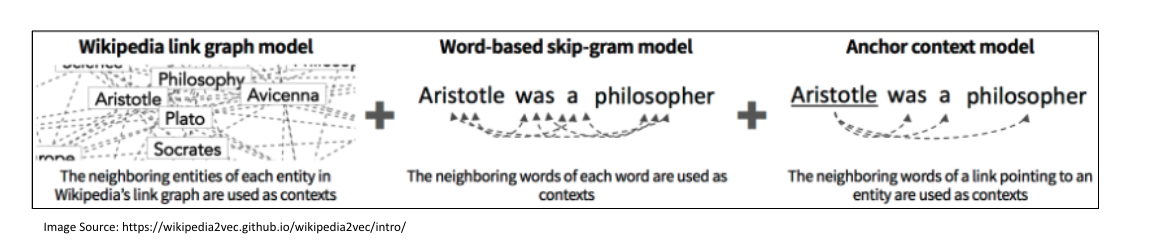
The model jointly learns word and entity embeddings from Wikipedia where similar words and entities are close to one another in the vector space. It comprises of three submodels namely Wikipedia Link Graph Model, Word-based skip-gram model, and Anchor context model.
Wikipedia Link Graph Model comprises of an undirected link graph in which the nodes are the Wikipedia entities and there exists an edge between two nodes if the page of one entity links to the other or if both pages link each other. It learns entity embeddings by predicting neighboring entities in the graph.
Word-based skip-gram model learns word embeddings by predicting neighboring words given each word in a text contained on a Wikipedia page.
Anchor context model learns embeddings by predicting neighboring words given each entity and aims to place similar words and entities near one another in the vector space
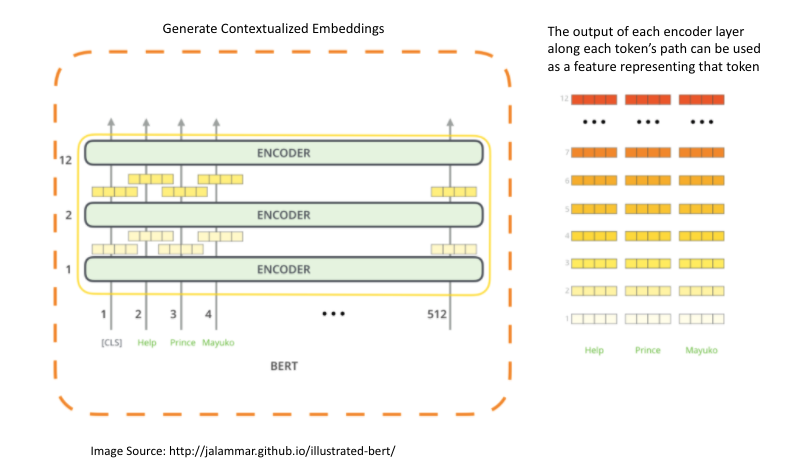
Bidirectional Encoder Representations from Transformers is a contextual information based embedding approach in which pretraining on bidirectional representations from unlabeled text by using the left and the right context in all the layers is performed. BERT makes use of Transformer, an attention mechanism that learns contextual relations between words (or sub-words) in a text. In its vanilla form, Transformer includes two separate mechanisms — an encoder that reads the text input and a decoder that produces a prediction for the task. Since BERT’s goal is to generate a language model, only the encoder mechanism is necessary. The encoder reads the entire sequence of words at once. Therefore it is considered bidirectional, which allows the model to learn the context of a word based on all of its surroundings.
Character embedding represents the latent representations of characters trained over a corpus which helps in determining the vector representations of out-of-vocabulary words. Character level embedding uses one-dimensional convolutional neural network (1D-CNN) to find numeric representation of words by looking at their character-level compositions.
Entity Typing
Entity Typing in the task of predicting types of entities in a Knowledge Graph and it plays a vital role in Knowledge Graph construction and completion.
The embedding of the entity names are generated using Neural Language Models (NLMs). To do so, pre-trained Word2Vec model on Google News dataset, GloVe model pre-trained on Wikipedia 2014 version and Gigaword 5, Wikipedia2Vec model pre-trained on English Wikipedia 2018 version, and pre-trained English character embeddings derived from GloVe 840B/300D dataset are used with a vector dimension of 300. The average of all word vectors in the entity names is taken as the vector representation of the entities. For BERT, the average of the last four hidden layers of the model is taken as a representation of the names of entities and the dimension used is 768.
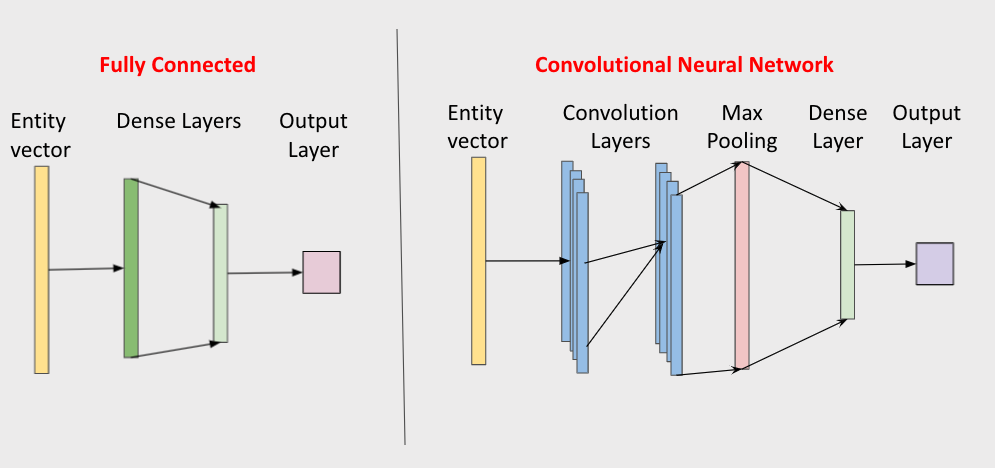
Two classifiers have been built on top of the NLMs:
Fully Connected Neural Network (FCNN), and
Convolutional Neural Network (CNN).
A three-layered FCNN model consisting of two dense layers with ReLU as an activation function has been used on the top of the vectors generated from the NLMs. The softmax function is used in the last layer to calculate the probability of the entities belonging to different classes. The CNN model consists of two 1-D convolutional layers followed by a global max-pooling layer. ReLu is used as an activation function in the convolutional layers and the output of the pooling layer is then passed through a fully connected final layer, in which the softmax function predicts the classes of the entities.
Datasets
The experiments are conducted on the benchmark dataset DBpedia630k extracted from DBpedia consisting of 7 non-overlapping classes with 560,000 train and 70,000 test entities. The classes are:
dbo: Person,
dbo: Organisation,
dbo: MeansofTransportation,
dbo: Place,
dbo: Animal,
dbo: Plant, and
dbo: Work.
Furthermore, to evaluate the approaches independently of DBpedia, an additional test set composed of entities from CaLiGraph. It is a Wikipedia-based KG containing entities extracted from tables and enumerations in Wikipedia articles. It consists of 70,000 entities that are unknown to DBpedia and are evenly distributed among 7 aforementioned classes.
Results
Embedding Models
Types in Labels
No Types in Labels
CaLiGraph Test set
FCNN
CNN
FCNN
CNN
FCNN
CNN
Word2Vec
80.11
46.71
72.08
44.39
48.93
25.91
GloVe
83.34
54.06
82.62
53.41
61.88
31.3
Wikipedia2Vec
91.14
60.47
90.68
57.36
75.21
36.97
BERT
67.37
62.27
64.63
60.4
53.42
35.55
Character Embedding
73.43
58.13
72.66
58.3
54.91
45.73
Our Amazing Team
Russa Biswas
FIZ Karlsruhe Leibniz Institute for Information Infrastructure, Germany
Radina Sofronova
FIZ Karlsruhe Leibniz Institute for Information Infrastructure, Germany
Mehwish Alam
FIZ Karlsruhe Leibniz Institute for Information Infrastructure, Germany
Nicolas Heist
University of Mannheim, Germany
Heiko Paulheim
University of Mannheim, Germany
Harald Sack
FIZ Karlsruhe Leibniz Institute for Information Infrastructure, Germany
How to cite the paper
@inproceedings{biswas2021judge,
title={Do Judge an Entity by its Name! Entity Typing using Language Models},
author={Biswas, Russa and Sofronova, Radina and Alam, Mehwish and Heist, Nicolas and Paulheim, Heiko and Sack, Harald},
booktitle={18th Extended Semantic Web Conference (ESWC), Poster and Demo Track},
year={2021},
organization={Springer}}